Introduction
A few interesting topics came up lately revolving AI, and one such topic surrounded “quizlettes” that could be made available to students based off a lecture.
A recent weekend project was to build a pipeline to develop such a solution, and presesent it to a few groups to demonstrate what AI can do.
In this specific example, a pipeline was built that takes a Youtube video, downloading the video then running it through various processing steps where, in the end, we get a PDF of exercises related to the content of the video. In this blog post, and sample code, I used a basic math course I found by Math Antics [1] on Youtube.
High Level Overview
Often times when performing a large process like this, it’s best to break down the problem into smaller, discrete, components then tie them together in the end. I call these “pipelines”, and utilize that term when talking with others. “Pipelines” in this context means one script running another script, and so on until we get the ending result.
Visually, this looks like:
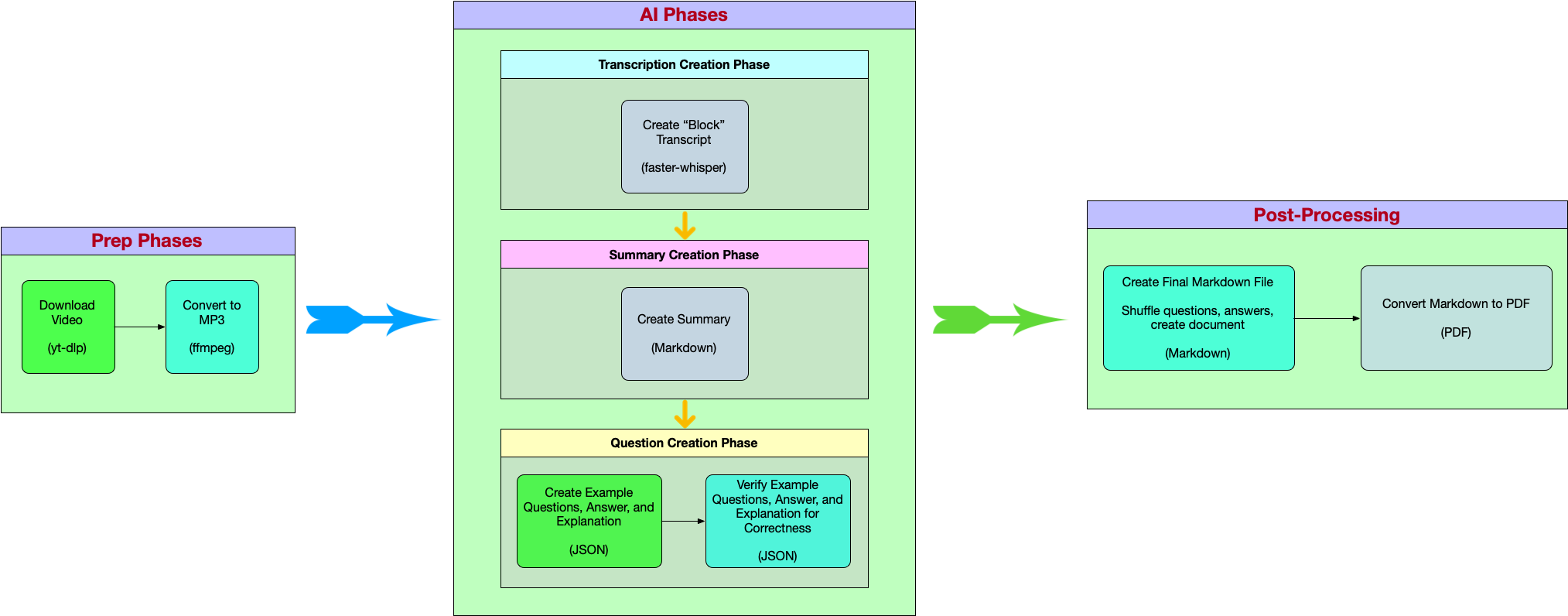
Detailed Explanations
I would like to warn the reader at this point that there’s far more detail below than I normally go into Python. If you’re interested in more the conclusion of this work, you can go to [[#Testing Results and Conclusion]]. If you’re familiar with Python already, and just want the code, then head to [[#Code Example]]. The details below will go line-by-line through the scripts, with the aim of teaching some Python along with how LangChain works and how I’m using it.
Prep Phases (Downloading and Conversion)
This step is fairly simple, and the script for it is quite simple. We use an Open Source project called yt-dlp [2]. This is a command line program that can be used to download videos from various sites, including Youtube. We have some options in this area, we can
either downloading the MP3 itself, or the video then convert. Because of the business case that I’d be eventually provided some video files to process,
I opted in this step to download the video and process the MP3 out myself. The code, as an example, is below:
#!/bin/sh
pushd no_git/
rm *.vtt *.mp4 *.mp3
youtube-dlp --write-subs --sub-lang en https://www.youtube.com/watch?v=KzfWUEJjG18
ffmpeg -i 'Math Antics - Basic Probability [KzfWUEJjG18].mp4' -q:a 0 -map a 'Math Antics - Basic Probability [KzfWUEJjG18].mp3'
popd
In the above, we have a few things going on:
- We cd into
no_gitwhere we’ll keep the intermediate pipeline steps. - We remove the existing files
- We download the Math Antics - Basic Probability [3]
- We run
ffmpeg[4], which is used for various video and audio operations, to convert the file to an MP3.
AI Phases (Transcript, Summary, and Assessment Questions)
The AI processes are the longest portion of this project - both in complexity, and execution time. There are three portions of this pipeline, and there’s a strict dependendency between each element of this workflow. High level, you can define different models for different portions of each pipeline.
Transcription
Transcription, also called Speech to Text (STT) [5], can use multiple technologies or endpoints to be handled. One version is Whisper by OpenAI [6]. Another is Azure AI Speech [7]. I’ve used all of these, but now-a-days, I use Faster Whisper [8]. It’s the fastest, and has been the most accurate, for my needs. I run this locally on my AI server, and it’s reachable from an OpenAI endpoint.
One thing worth mentioning about transcription. You can either get transcripts that are in VTT format[9], or what I call “block” format. The VTT format is quite verbose, showing the time in the video when something is spoken, and the content of what was spoken. One may assume that this is better for the AI, to give it more context, but through experimenting with this project (and my other pipelines), I’ve found that the VTT format does NOT add much value in the way I utilize transcripts. The significant downfall of the VTT format is that it adds to our token counts drastically going forward. “Block” format basically has the entire transcript as one paragraph, and has been preferred on my end to aid in token counts.
The code for this is fairly simple, and is shown below:
from pathlib import Path
import dotenv
from openai import OpenAI, DefaultHttpxClient
_env = dotenv.dotenv_values("../.env")
_llm = OpenAI(
base_url=_env["OPENAI_TRANSCRIBE_BASE"], api_key=_env["OPENAI_API_KEY"],
http_client=DefaultHttpxClient(
verify="../ai.pem",
)
)
def transcribe_audio(audio_file_path: str) -> str:
with open(audio_file_path, 'rb') as audio_file:
transcription = _llm.audio.transcriptions.create(model=_env["OPENAI_MODEL_TRANSCRIBE"], file=audio_file)
return transcription.text
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Please provide the filename to the MP3")
sys.exit(1)
audio_file_path = sys.argv[1]
print(f"Running transcription on: {audio_file_path}")
audio_transcript = transcribe_audio(audio_file_path)
out_file = Path(audio_file_path).with_suffix(".transcript.txt")
with open(out_file, 'w') as f:
f.write(audio_transcript)
print(f"Transcription saved to: {out_file}")
In the above code, we have the following (read top down):
- Imports of our required libraries.
dotenvallows me not to store credentials in my code, and theopenaiallows the endpoints to be created. _envsimply loads the environmental variables to get the endpoint information, where_llmis defined. Theai.pemis for SSL verification to my server, which does run under SSL in a subdomain in my internal network, this is to verify since it won’t use the system certs.- The function,
transcribe_audio, takes one argument - the path to the file. The Whisper and Faster-Whisper endpoints can accept even WAV or MP3 formats for transcription. This is one giant operation, with no streaming. Once it’s complete it’s set to the variabletranscription, which the text is returned for further use. - The
__name__ == "__main__"block is run if we runpythondirectly against the Python file, but isn’t run if we import functionality from here into another script. It does the following:- We expect one argument, which is the path to the MP3 itself. There’s always at least a count of 1 for
sys.argv, even without arguments. - We assign the
argv[1]toaudio_file_pathand run the function to transcribe the audio. - We then utilize the same basename as the audio file, but use
.transcript.txtinstead of.mp3. So the name stays consistent. - We open that file, and write to it.
- We expect one argument, which is the path to the MP3 itself. There’s always at least a count of 1 for
Summarization
The next part of the pipeline is to create a summary. The summary is the an explanation of what was covered in the video, including the topics discussed. This portion of the pipeline has many uses, and I have 3 other projects that use this same methodology. It’s very powerful, and adaptable to a large number of domains and uses.
import sys
from pathlib import Path
import dotenv
import httpx
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
_env = dotenv.dotenv_values("../.env")
_llm = ChatOpenAI(
openai_api_base=_env["OPENAI_API_BASE"],
openai_api_key=_env["OPENAI_API_KEY"],
model_name=_env["SUMMARIZATION_MODEL_NAME"],
temperature=0.4, streaming=False, max_tokens=2048,
http_client=httpx.Client(
verify="../ai.pem",
)
)
Much of the above should look very similar to what we did in the transcription portion. A few things have changed:
- The
model_namehas changed. In the transcription portion, we were using Faster-Whisper, and this time we’re using an LLM model to do the summarization. I’ll talk more about this below. - The addition of
temperature,streaming, andmax_tokenstemperaturedenotes how deterministic our model needs to be. The larger this number, the more variance we have between runs. In general, if we’re trying to be more precise, it’s better to set a temperature on the lower scale. If you want more creative output, you can crank this up.streamingcan be used to allow partial results from the LLM to be sent back in blocks. This is incredibly useful in a chatbot, but isn’t useful here. Furthermore, adding streaming support requires a callback, which would complicate the code considerably.max_tokensdeals with the max tokens that can be generated. This is an optional argument.
A keen eye may have noticed the use of ChatOpenAI use here vs OpenAI in the transcription process. We’ll see how the chat messages are developed
below, but that’s the main difference. At a high level, what this does is format the messages in a way that the server can set up the prompting better for you. So if the backend changes what goes where, they can keep backwards compatibility with this abstraction layer.
_system_prompt_text = """You're an expert in creating summaries based off lecture recordings. You're precise, and detailed.
Your goal is given a lecture recording, to create a summary of the lecture. You're expected to create a proper summary given
the context of the lecture. You aren't to hallucinate, or expand on the lecture, but to provide a summary of the lecture."""
_user_prompt_noVTT_text = """Above you were provided a lecture recording. The transcript is by one individual, and is presented in
order of which topics were discussed. You're to summarize the Mathematics lecture provided. BE VERBOSE!
When creating the summary, multiple sections are important to include. The first is the "Summary" section, which is a
high level summary of the lecture. This should be a paragraph, minimum, and can be longer. It should be high level.
The next section is the topics discussed. This should be a list of the topics discussed, separated by a colon, and details about that topic.
An example format is given below:
# Summary:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute
irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat.
# Topics Discussed:
- **Lorem ipsum dolor sit amet**: consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua
- **Ut enim ad minim veniam**: quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat
- **Duis aute irure dolor**: in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur
"""
_novtt_summarize_template = [
("system", _system_prompt_text),
("system", "{transcript}"), # <-- Variable
("user", _user_prompt_noVTT_text)
]
In the above code, we’re getting some basic stuff setup for our LLM call. The system prompt helps set the context for what’s to come. Often times, it’s best to give various restrictions, context, and other information that helps the LLM. The user prompt is the specific instruction. It comes in last, and has the greatest impact on what the LLM does with the information. It often helps to give the LLM an example of the output you wish to receive. This is called “few-shot” prompting[10], and I wrote extensively [11][12] about it in the past.
In the end, we assign a list of tuples to a variable, that will be handled later. The “system”, and “user” denote roles in from the Chat Completion process. The “Moving from Completions to Chat Completions in the OpenAI API” [13] describes this quite well.
def summarize_text(transcript: str, template: list) -> str:
prompt = ChatPromptTemplate.from_messages(template)
chain = prompt | _llm
result = chain.invoke({"transcript": transcript})
return result.content.strip()
def load_transcript_and_run(transcript_file: Path, template: list, out_file_name: Path) -> None:
with open(transcript_file, 'r') as f:
transcript = f.read()
summary = summarize_text(transcript, template)
with open(out_file_name, 'w') as f:
f.write(summary)
Two functions are defined above to help make this repeatable, and something I can plug into other scripts as well. The first function, summarize_text is the only one that directly calls the LLM, and it uses LangChain [14] to make that happen. LangChain is not a requirement for this process, especially one this small, but it’s a library I heavily use, and is in most of my projects at this point. There are a number of abstractions in the backend that help compose the messages (see the from_messages method), to the chaining together chain = prompt | _llm. You can chain other operations, and pretty much as many as you want, and it’ll run one after the other and pipe the results to the chained operations. Once the chain is defined, the chain.invoke is called. This takes a dictionary for our variables present in our template. The variable is defined in our tuple, and also in our messages. It’s called transcript, which we feed in the entire transcript.
One area of note on this process is that this is called Stuffing [15]. The idea is that the entire transcript comes into the prompt, and all of it is sent to the LLM. It’s worth talking about types of transcripts a bit more.
- “vtt” files are very verbose files that include a start and end time, along with what was discussed during that time slot. They’re quite powerful, but expensive in terms of tokens. If you have a very long meeting, thus a long transcript, you can in theory run over the limit.
- “text” files, which I’ve been calling block format in the introduction, is much more dense.
One may think that “vtt” formats may provide a much better AI summarization, but in my experience it isn’t any better. To save on tokens, for a step like this, I strongly encourage sticking with the block format whenever possible.
The next function, load_transcript_and_run is really a glorified wrapper. It reads the transcript passed into it, calls summarize_text with the template passed in, and then writes the output of that summarization. I have it setup this way because in this version, I was running both block and VTT formats through the LLM when looking at differences.
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Please provide the filename to the MP3")
sys.exit(1)
transcript_file = Path(sys.argv[1]).with_suffix(".transcript.txt")
transcript_file_out = Path(sys.argv[1]).with_suffix(".novtt_summary.md")
print("Summarizing Non-VTT file")
load_transcript_and_run(transcript_file, _novtt_summarize_template, transcript_file_out)
print("Summarization complete")
In Python, if you have a block like this, it gets executed when you run python <FILENAME>.py, but not run if you import this file from another Python file. Because the wrapper is a bash script, it runs each script in the pipeline. First, we verify the number of arguments are correct, and exit if it’s too few. Second, we get our paths, which relies on the MP3 file being used. After that, it calls the load_transcript_and_run function with the arguments which also saves the result.
This is all run by executing:
python3 03_create_summary.py 'no_git/Math Antics - Basic Probability [KzfWUEJjG18].mp3'
Assessment Questions
The next part of the pipeline is creating the assessment questions, identifying the answer, and the reasoning for the answer. This pipeline step is the most complicated, and involves two primary steps:
- Generation of Questions/answers - We request a JSON object for this purpose, as it’s easier to programmatically deal with later in the process.
- Verification of Questions/answers - We pass in the result of step 1, to give the AI an opportunity to verify its works and change something if it needs.
It may sound strange to have to verify, but to explain this, I need to explain how LLMs work [16]. An LLM is basically a predictive model . It predicts words based in part what came before, but also what can come after. It’s not terribly complicated, but it predicts multiple options, ranks, then picks the top one then continues on. What can happen is if context is too long, that certain things are forgotten or misrepresented. While the number of tokens coming in, for this short video, is smaller in number, and the resulting tokens we want out is also small, we want to avoid potential hallucination. This is a form of LLM Guardrails [17], where we try and ensure that the AI got the answer right to begin with.
It’s a lot to unpack, so let’s look at some code:
_system_prompt_text = """You're an expert in creating test questions based off the lecture recordings. You're precise, and detailed.
Below, you're provided the transcript of the lecture, the summary of the lecture, and the topics discussed. Your goal is to assist
in creating accurate test questions based off the lecture. You're expected to follow the user instructions precisely."""
_user_prompt_text = """Above you were provided a lecture recording transcript. The goal in this step is to create 10 test questions, and answers
to better assist in the learning process. The questions MUST be related to the topics discussed in the lecture, and must geared toward
the level of the lecture. The questions must be multiple choice, with the answer being a single choice. For each element of the list, I expect the following:
- question: The question to be asked.
- choices: A list of 5 (FIVE) choices for the question, the correct answer must be a part of that list.
- answer: The correct answer to the question, must be one of the choices.
- answer_explanation: An explanation of why the answer is correct.
The resulting form must be presented as a JSON object, in the format below:
[{{ "question": "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua?",
"choices": ["Lorem impsum dolor", "consectetur adipiscing elit", "colore magna aliqua", "Sed do eiusmod tempor", "incididunt ut labore"],
"answer": "consectetur adipiscing elit",
"answer_explanation": "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua"
}}, ...]
Please provide 10 such questions to test the listener using examples from the lecture at the level of which the lecture was aimed.
If you're unable to create 10, please provide as many as you can. If you're able to create more than 10, then please provide the 10 most relevant questions to the lecture.
Please do NOT add any commentary, or any additional information except the JSON object as described above! BE QUICK! Don't overthink it!
"""
_generate_question_template = [
("system", _system_prompt_text),
("system", "{transcript}"),
("system", "{summary}"),
("user", _user_prompt_text)
]
What we see here is very similar to what we’ve seen already. I omitted the OpenAI endpoint creation, but leaving the prompts. The _system_prompt_text
helps set the tone, the role, that the AI model should take. The _user_prompt_text uses few shot prompting [10] [11], which we talked about above.
The main difference from the previous time we saw this is that I’m requesting a JSON object. In LangChain, the {} block denotes a variable we’re passing in. To get around LangChain
viewing this as a variable, we have to use {{}} around our dictionary element. In the last line, we’re creating our list of tuple elements that will pass in the system prompt, transcript, summary, and our request.
For the verification steps, we need the following:
_verification_prompt_text = """Above you are provided a lecture recording transcript, and after that, the test questions and answers as a JSON list.
Your goal here is to verify your work. Please look over the test questions and the answer you denoted. Please ensure that the question relates
to the lecture, and the the answer you denoted is correct, mathematically speaking.
If you find that the question is not related to the lecture, or the answer is incorrect,
please correct it. The format you received this in is a JSON object, the result expected is the same JSON object!
No further comment is requested, ONLY the JSON object with correct questions and answers ONLY."""
_verification_template = [
("system", _system_prompt_text),
("system", "{transcript}"),
("system", "{test_questions_answers}"),
("user", _verification_prompt_text)
]
There are two things we didn’t see previously. First, is how the prompt text is setup when we want to restrict the output. Take special note to the whole “No further comment is requested”. If this type of request is omitted, the LLM will say something like “Sure, here’s what you requested … Please let me know if I can be of better help”, which of course, can’t be programmatically parsed properly. It’s worth noting that even this directive isn’t 100% guaranteed to work where the dictionary comes out in exactly the same format. For example, in some runs, it gave me a new key for “corrected” and whether it was correct or not. For the most part, since I can ignore that field later on, I don’t mind it being flexible here, as long as I get the required JSON object returned.
The other part we haven’t seen in the ("system", "{test_questions_answers}") portion, where we can pass in output from one chain to another. LangChain is quite flexible, and you can quite literally do this all in one chain.
def generate_questions(transcript: str, summary: str, tries_left=3) -> list[dict[str, str|list[str]]]:
prompt = ChatPromptTemplate.from_messages(_generate_question_template)
chain = prompt | _llm
result = chain.invoke({"transcript": transcript, "summary": summary})
try:
return_object = json.loads(result.content.strip())
return return_object
except json.decoder.JSONDecodeError:
if tries_left == 0:
raise RuntimeError("Failed to generate questions")
else:
print(f"Failed to generate questions, trying again. Tries left: {tries_left-1}")
return generate_questions(transcript, summary, tries_left - 1)
def verify_questions(transcript: str, test_questions_answers: list[dict[str, str|list[str]]], tries_left=3) -> list[dict[str, str|list[str]]]:
prompt = ChatPromptTemplate.from_messages(_verification_template)
chain = prompt | _llm
result = chain.invoke({"transcript": transcript, "test_questions_answers": json.dumps(test_questions_answers)})
try:
return_object = json.loads(result.content.strip())
return return_object
except json.decoder.JSONDecodeError:
if tries_left == 0:
raise RuntimeError("Failed to verify questions")
else:
print(f"Failed to verify questions, trying again. Tries left: {tries_left-1}")
return verify_questions(transcript, test_questions_answers, tries_left - 1)
These two functions help to run the two steps we spoke about above. Earlier, I mentioned how we could use LangChain to chain all this together into one set of calls. The reason why I don’t do that is to make debugging a lot easier.
In the above functions, I can set breakpoints and evaluate the output. Since both functions are nearly identical, I’ll describe just the generate_questions function.
In generate_questions we accept 2 mandatory arguments and one optional argument. The mandatory arguments is the transcript, and summary which are variables
in our pipeline. The optional argument is used since this function is recurrsive. We take the list of tuples and compose it into a Prompt Template object
which will later be decomposed by the provider. We define a chain, which is denoted by the pipe (|) which takes our prompt, and passes it to the _llm object, which
is our definition of ChatOpenAI described far above. We then run chain.invoke, passing in our variables to the chain, which does a string replacement, and
physical call to the LLM. The result of this is passed to a try/catch block. What this does is attempts to decompose the object into a JSON object, and if successful, then will
return that object. If not successful, we then recurrsively call the same function with one less try.
At the end of all this, we simply output to a file to process later:
out_file = Path(mp3_file).with_suffix(".questions.json")
with open(out_file, 'w') as f:
json.dump(questions, f, indent=4)
print(f"Questions saved to: {out_file}")
Post Processing (Markdown Creation, PDF Creation)
After this is all done, we can create a formatted file then to print out, or edit on an iPad. Overall, the below is more simple Python. First, we need to generate a Markdown file.
def generate_full_md_file(summary: str, questions: list[dict[str, str|list[str]]]) -> str:
full_md = f"""# Lecture Summary
{summary}
# Questions
"""
random.shuffle(questions)
options = ['A', 'B', 'C', 'D', 'E']
answers = []
for ix, q in enumerate(questions):
full_md += f"## **{ix+1}:** {q['question']}\n"
random.shuffle(q['choices'])
for i, c in enumerate(q['choices']):
if q['answer'] == c:
answers.append(f"**{ix+1} - {options[i]}**: {c}, {q['answer_explanation']}")
full_md += f"- {options[i]}: {c}\n"
full_md += "\n\n"
full_md += '\\newpage\n'
full_md += "# Answers\n"
for a in answers:
full_md += f"- {a}\n"
return full_md
The input for this takes the summary and our questions/answers object from our LLM calls, and shuffles the answers and adds them to the answer block in a random order with the question listed. We then define a newpage so that we can print the answers to for checking.
After this is run, we can just convert to a PDF, using Pandoc.
def create_pdf_from_md(md_file: Path, pdf_file: Path) -> None:
print(f"Converting {md_file} to {pdf_file}")
# Run pandoc to convert the markdown file to a PDF, calling through shell
pandoc_cmd = f"pandoc -V geometry:margin=1in -o '{pdf_file}' '{md_file}'"
os.system(pandoc_cmd)
Code Example
You can view an example of the output from the time I ran this from Here
You can view the Github repo Here
Testing Results and Conclusion
Truth be told, most of this article was done nearly 8 months ago, and it’s been touched up on since then. This pipeline I use in a similar fashion for summarizing books - which I may write about in the future. The accuracy of this has been fairly good in my view when I originally did this, but since then things have changed a fair amount. The advent of “thinking models” actually make this even better now. So, one could simply reduce some of the steps here. One reason for the “double check” operation I have in the verify_questions is a mini version of what thinking models do already. That step can be largely removed.
That said, exercises like this can be quite helpful to reinforce learning. Not necessarily just for school-age people, but for those of all ages who are trying to learn new skills.
References
- Math Antics YouTube Channel
- yt-dlp Github Page
- Math Antics - Basic Probability
- FFmpeg Website
- Speech Recognition - Wikipedia
- Whisper - OpenAI
- Azure AI Speech
- Faster Whisper - Github
- WebVTT - Wikipedia
- What Are Zero-Shot Prompting and Few-Shot Prompting
- TheDarkTrumpet - Generative AI Flashcards
- TheDarkTrumpet - Effective prompting with AI
- OpenAI - Moving from Completions to Chat Completions in the OpenAI API
- Langchain - Home Page
- Langchain Tutorial - Summarization
- CEST - The Surprising Power of Next Word Prediction: Large Language Models Explained, Part 1
- LLM Guardrails: Types of Guards
