Introduction
Around June of 2023, I started really getting into running my own AI models. While I plan on creating a more introductory post regarding AI eventually, I figured I’d share a project I’ve been working on, and why I find AI so amazing.
What is AI?
AI stands for Artificial Intelligence [1]. It’s a class of Computer Science that allows for machines to learn much like humans learn - and that’s by seeing patterns in information, and essentially learning how to predict based off prior knowledge.
The analogy I gave in a recent presentation is we might learn a new language. Or, potentially easier, is how children learn their language from their parents. We as humans see patterns (be that how something is done, said, social conventions, etc.) and emulate those on a daily basis.
AI is basically allowing computers to do this.
The Project - What am I trying to accomplish?
I enjoy reading and studying, I’ve written quite a bit about it in the past [2] [3]. I don’t believe learning ends at finishing a book. You also need to memorize and implement the concepts in the book. I’ve recently been reading a book called “Generative AI with LangChain” [4], which is quite a good book on the current state of AI in general with very useful “forks” to other information.
Either way, around page 103 of the book talks about summarizing documents. I’ve found the code provided in the Github repo [5] not particularly useful, but it did turn into an obsession of mine for a few days now learning about Map-Reduce [6], which I’ve developed a number of programs and notebooks off of. Which lead instinctively to generating Anki Decks.
What is Anki?
Anki [7] a program that helps with rote memorization, but also with remembering important concepts. These can be simple flashcards (which I think all students have created in some fashion), or Cloze sentences [8].
In Anki terms, a close sentence takes the format of something like:
A {{c1::cat}} is an adorable creature. It has {{c2::4}} legs, and often a {{c3::large, furry stomach}}.
In the above example, there are 3 flashcards created within Anki. They would be:
- A _____ is an adorable creature. It has 4 legs, and often a large, furry stomach.
- A cat is an adorable creature. It has _____ legs, and often a large, furry stomach.
- A cat is an adorable creature. It has 4 legs, and often a _____.
When I create flashcards, they’re almost entirely Cloze-based sentences. First, they’re more interesting and second you can test based off concepts instead of rote memorization. I could write an entire post on this concept and how it aids in learning.
Implementation of the Project, High Level.
The implementation had a few major phases, much of this is automated. There’s a human component at the beginning, and at the end.
- Obtaining the ePub (or PDF) - We need the file to start with. This can be obtained a number of ways.
- Convert to PDF (if source is not PDF) - The LangChain loader I’m using relies on PDFs to be the input. I’m tempted to take a different approach to #1 and #2.
- Splitting the Document - We have a context limit in LLMs, it can’t read the entire document. So the PDF Loader has an option to split the text into chunks.
- Summarize/Pull the Most Important Information - On each document “split”, we need to reduce the amount of tokens so we can feed it back into the model at the end.
- Final LLM call and Formatting - We take the information from #4 and feed it back into the model. Here’s where the best way we can format output happens.
- Create Anki Deck - This has multiple parts, but is relatively straightforward. We take the information from #5 and create our “cards” which then get inserted into our “deck”, which then gets imported into Anki.
The steps that are manual, in the above is primarily #1 and #2. The rest is entirely automated.
The whole process, graphically, is below:
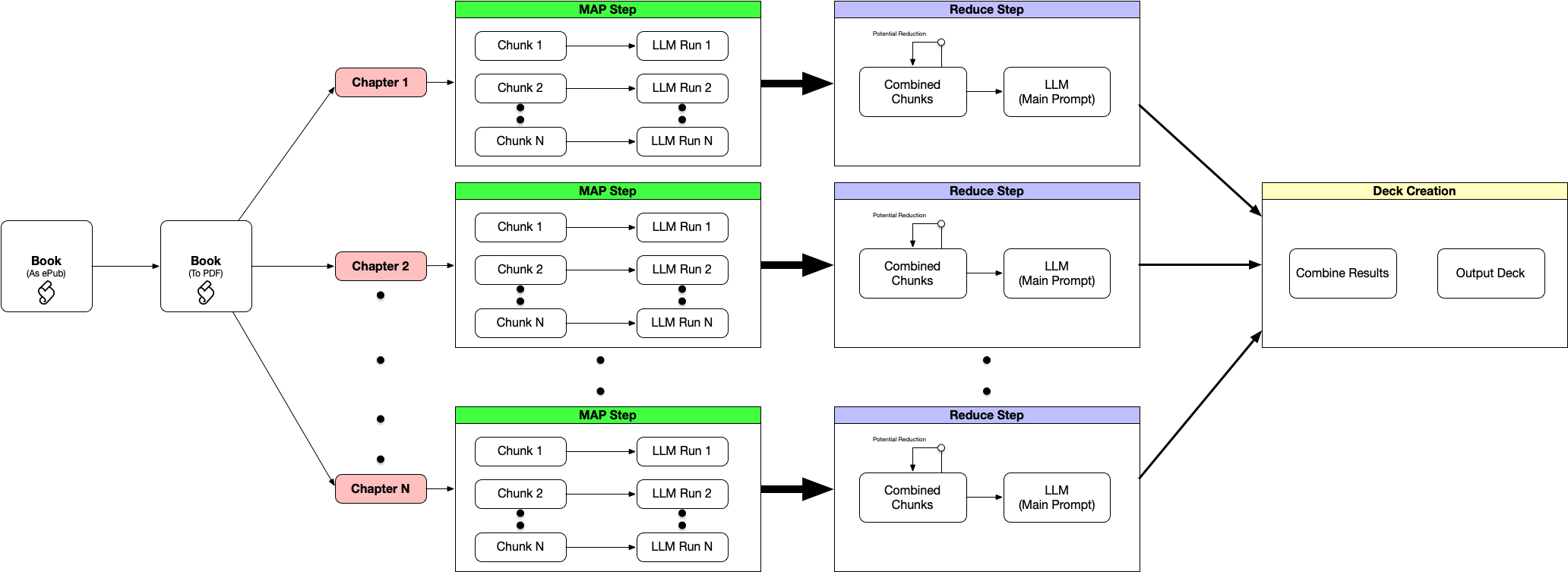
Preparing the Data Set (Steps #1 and #2)
LangChain has many tools that help with this particular problem, and one category of tools is called “Document Loaders”. They take documents of various types (PDF, Text, Markdown, etc.) and can load and chunk the information. For this, I used the PDF loader [9].
But before I did that, I needed to prepare a PDF for loading. The book I have for “Generative AI with LangChain” is in ePub. I used Calibre [10] to convert the ePub to PDF. I then went through the PDF manually in preview.app, and pulled each chapter into their individual files. In the end, I had the following files:
generative-ai-01.pdf
generative-ai-02.pdf
generative-ai-03.pdf
generative-ai-04.pdf
generative-ai-05.pdf
generative-ai-06.pdf
generative-ai-07.pdf
generative-ai-08.pdf
generative-ai-09.pdf
generative-ai-10.pdf
The reason I chose to do it by chapter, vs the entire book are as follows:
- Easier to test - The more chunks I have to run, the longer this process takes. Even on quite advanced hardware, it’s not simple debugging the output. Smaller = better.
- Context Size - I really want to get as many flashcards as possible, as it’s easier for me to prune the ones I find of low quality. If I summarize “too much”, then I’ll lose a lot of definitions that otherwise would have been caught.
The context size is a recurring theme for all of this.
Architecture Decisions
Before moving onto the LLM and LangChain steps, I think it’s important to highlight what I’m running, what you may want to try running against, and why it matters.
First, it’s worth mentioning that not all models are created equal. One thing I find people misunderstanding is that their line of thought stops at the ChatGPT/OpenAI line of products. There’s very little thought about even those models (e.g. 3.5 or 4, and their respective context sizes).
There are many models out there, and some fine-tuned that are frankly, quite amazing. You can also run much of this on your own hardware (especially if you sink some money into it). The model I chose to use for this is the MixtralOrochi8x7B [11] model. There are a few reasons for this:
- It’s based off the same concept as the Mixtral Architecture [12] - This architecture of a collection of fine-tuned models is simply amazing.
- It’s uncensored - This is a big deal for me, maybe not for you. I don’t believe my model should censor what it answers or how it answers. This is a philosophical choice of mine.
- It’s a good general purpose model - I found this sufficient for all areas of AI lately, not just this project.
I also much prefer the GGUF set of models, because I can up the context limit easily, and have better control over the quality of the model (Quantization[13]) that I get. I can balance memory, performance, and accuracy much easier.
Now for the hardware. If you’re planning on running something like this on a laptop or lower-grade consumer hardware, good luck. If you have limited hardware, I’d try for either the Mistral 7b model (base one), or something in the 20B range. I’m running this on a NVIDIA RTX 6000 Ada Generation[14]. The model, though, takes up about 32GB or video RAM. This is with 32k context size, which is quite high (and equal to ChatGPT 4). Which, given the complexity of this model, is quite low memory usage.
There are options to spin up/use this in the cloud though, but that’s outside the scope of this. Just note that cloud usage can get very expensive.
For the backend (the portion that does the LLM work itself), I use Text-Generation-WebUI[15]. It’s a very easy to use Gradio frontend to a number of loaders. Since I use GGUF, I tend to use the llama.cpp loaders in most general cases. It provides a nice interface for using it like a chat bot, notebook, or even to start testing some document training (although I’d fine-tune, or more complex operations elsewhere).
LangChain Steps (Steps #3, #4, and #5)
LangChain works off the concept of Chains. Chains are described by Generative Ai with LangChain as[16]:
Chains are a critical concept in LangChain for composing modular components into reusable pipelines. For example, developers can put together multiple LLM calls and other components in a sequence to create complex applications like chat bot-like social interactions, data extraction, and data analysis. In the most generic terms, a chain is a sequence of calls to components, which can include other chains.
You can think of it as operational links, almost like functions within a programming language.
All of this relies upon a base LLM to call to. There are a number of LLM providers[17] - including OpenAI compatible, Azure, etc.
Text-Generation-WebUI recently changed their API specs to follow the OpenAI standards, which makes example code much easier to work with, even if it’s a bit limiting. But the nice thing about LangChain is it’s easy to switch out providers and chains since the API is pretty consistent between them.
The LLM creation is:
llm: ChatOpenAI = ChatOpenAI(openai_api_base=env['HOST'], openai_api_key=env['KEY'], model_name=env['MODEL'], temperature=0.4, max_tokens=int(env['MAX_TOKENS']))
The .env contents are:
HOST="http://workstation.local.tdt:5000/v1"
MODEL="mixtralorochi8_7b.Q4_K_m.gguf"
KEY="1234"
MAX_TOKENS=12288
Splitting the Document (Step #3)
Splitting the document is by far the easiest step, and is only a few lines of code to do:
pdf_loader: PyPDFLoader = PyPDFLoader(filename)
docs: list[Document] = pdf_loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=12288, chunk_overlap=0))
The first line, where pdf_loader is set simply loads the PDF. The second line actually splits it. A few things to note here:
- The
chunk_sizeneeds to be in reference to what your context size can be. - In my experience, this is the max it’ll end up being. But, if you have pages in a document, it appears to split based off the page.
Summarize/Pull the Most Important Information (Step #4)
In Step #3, we’re given a number of “documents”, as pages, from the chapter. The next part is to reduce each of those documents to pull out what we want in the end.
def get_map_chain(llm) -> LLMChain:
map_template: str = """The following is a set of documents
{docs}
Based on this list of docs, please pick out the major concepts, TERMS, DEFINITIONS, and ACRONYMS that are important in the document.
Do not worry about historical context (when something was introduced or implemented). Ignore anything that looks like source code.
Helpful Answer:"""
map_prompt: PromptTemplate = PromptTemplate.from_template(map_template)
map_chain: LLMChain = LLMChain(llm=llm, prompt=map_prompt)
return map_chainIt’s important to note that nothing is run against the LLM at this point. We have one call that I’ll go through later, but this creates the chain for this specific operation. There’s still quite a bit going on though
map_template = ...- This is where we create our prompt. LangChain templates support insertions, that’s what the{docs}is doing. What’s actually sent to the LLM is an insertion of our document into that block, with our instructions at the end. This was largely taken from the tutorial for summarization [18]. Note the CAPS on certain portions here. I’m asking the LLM to focus on specific things to pick out of the document, not just summarize the contents.map_prompt = ...- This creates a Prompt Template, a class that contains our prompt.map_chain = ...- This creates the chain, and binds it to our llm object.
Final LLM call and Formatting (Step #5)
There are two major portions to this. First, we need to create the reduction step, then finally call the entire chain.
Reduction Step (Step #5a)
def get_reduce_document_chain(llm: ChatOpenAI) -> LLMChain:
# Reduce
reduce_template: str = """The following is set of definitions and concepts:
{docs}
Take these and distill it into a final, consolidated list of at least twenty (20) definitions and concepts, in the format of cloze sentences. The goal of this is that these sentences
will be inserted into ANKI. Please provide the final list as a FULLY VALID JSON LIST, NOT a dictionary!
An example of what I'm requesting, for output, should be formatted similar be the following:
["A {{{{c1::cat}}}} is a {{{{c2::furry}}}} animal that {{{{c3::meows}}}}.", "A {{{{c1::dog}}}} is a {{{{c2::furry}}}} animal that {{{{c3::barks}}}}, "a {{{{c1::computer}}}} is a machine that computes."]
Helpful Answer:"
"""
reduce_prompt: PromptTemplate = PromptTemplate.from_template(reduce_template)
# Run chain
reduce_chain: LLMChain = LLMChain(llm=llm, prompt=reduce_prompt)
# Takes a list of documents, combines them into a single string, and passes this to an LLMChain
combine_documents_chain: StuffDocumentsChain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="docs")
# Combines and iteravely reduces the mapped documents
reduce_documents_chain: ReduceDocumentsChain = ReduceDocumentsChain(
combine_documents_chain=combine_documents_chain,
collapse_documents_chain=combine_documents_chain,
token_max=15000)
return reduce_documents_chainThere’s quite a bit going on above, and I’ll glaze over some of the details. In a high level summary, we want to take the results of the map call (Step #4) and “stuff” them into one giant call to the LLM. In case this doesn’t all fit, we have a separate process that collapse it further (think of it chunking it up again). The token_max is for that purpose. Some things I want to highlight that are important are:
reduce_template = ...- This is another template, much like we used in step #4, but there’s more going on here:- Description of Intent - I assume that the model knows about Anki, and about Cloze sentences already. I indicate what I’m doing with the result of this.
- Requests for lower bound - I tell it exactly the minimum definitions I want. This is important, you want to be very clear as to your expectations. I rather prune information out, than have to add to it.
- I provide an example - This is called Few-Shot Prompting[19]. By providing a sample, I’m more likely to get what I want.
- I describe the output - I want to process this later, so I specify it as a JSON object, but not just any JSON object. I ask for specifically a list. This does matter.
token_max=15000- Going back to the context topic later. You may recall, I run 32k context, why am I asking for 15k-ish here? The reason has to do with the prompt + document + response count toward that max. If I ask for too much, my instructions can get cut off.
Call Entire Chain (Step #5b)
The steps #4, and #5a give us our components where we can call the final chain. This strings all the other chains together to run the pipeline, and return the result.
def run_chain(llm: ChatOpenAI, docs: list) -> None:
# Combining documents by mapping a chain over them, then combining results
map_reduce_chain = MapReduceDocumentsChain(
llm_chain=get_map_chain(llm),
reduce_documents_chain=get_reduce_document_chain(llm),
document_variable_name="docs",
return_intermediate_steps=False,
return_map_steps=True
)
result: dict[str, Any] = map_reduce_chain(docs)
return result
The above takes steps #4, and #5a and puts them together into one call. The nice thing about LangChain is that chains can call other chains, which is precisely what’s going on here. We have multiple sub-calls that are going on here, it’s not just one LLM call.
The one thing I’ll highlight here is the return_map_steps doesn’t need to be True. I prefer to have a bit more debugging information, since I’m outputting this to a JSON file so I can inspect the results. I’ll talk more about this in the Results and Quality section below.
Create Anki Deck (Step #6)
There’s a nice library for Python, called GenAnki[20] that I’m using for this process. The documentation is a bit lackluster, and I had to dig into the unit tests to really understand it better, but once you get it, it’s pretty simple.
anki_model: genanki.Model = genanki.Model(
rnd.randint(10000,100000000), # This is a random model ID
'ai-close-model',
fields=[
{'name': 'Text'},
{'name': 'Extra'}
],
templates=[
{
'name': 'ai-card',
'qfmt': '{{cloze:Text}}',
'afmt': '{{cloze:Text}}<br>{{Extra}}',
},
],
css=""".card {
font-family: arial;
font-size: 20px;
text-align: center;
color: black;
background-color: white;
}
.cloze {
font-weight: bold;
color: blue;
}
.nightMode .cloze {
color: lightblue;
}
""",
model_type=genanki.Model.CLOZE,
)
# ... some time later ..
def generate_anki_deck(contents: dict[str, list], out_file: str, deck_title: str) -> None:
anki_deck: genanki.Deck = genanki.Deck(
rnd.randint(10000,100000000),
deck_title)
for k,v in contents.items():
for item in v:
my_note: genanki.Note = genanki.Note(
model=anki_model,
fields=[item, k]
)
anki_deck.add_note(
my_note
)
genanki.Package(anki_deck).write_to_file(out_file)Without going line by line, the main summary is that we receive a dictionary (through the variable contents) in the function generate_anki_deck and an out_file. The key of the dictionary is the metadata including the chapter (e.g. generative-ai-01.pdf, but with nicer formatting, see the Full Code link below), and that key is used as the “extra” field, whereas the actual close sentence is the list element. The main reason why I like a metadata field is for the “Extras” field. It tells me where the flashcard came from, which makes it easier to track down and verify later.
So if we have a book with 10 chapters (like I do), we have a dictionary that has 10 items, with each item that should have a large sample of close sentences. We collapse all this information into one deck, which is then written to a file.
Full Code
I likely will deploy this as a full project long term, with both summarization and flashcard support. But for now, I’m hosting it as a gist at the following URL:
https://gist.github.com/TheDarkTrumpet/431852be731df2c783e7294107fad25a
The important note is that it relies upon a .env file to work though. You can replace all the .env stuff in code, or generate one. Mine is below:
HOST="http://workstation.local.tdt:5000/v1"
MODEL="mixtralorochi8_7b.Q4_K_m.gguf"
KEY="1234"
MAX_TOKENS=12288
Please also note that I haven’t tested this with OpenAI (I have specific reasons for this), so depending on the model you choose, you may need to change the MAX_TOKENS and associated parameters to match the model you choose.
Results and Quality
I’m quite happy with the results of this project so far. I found that there are some cards I wouldn’t include, and cards that I would have included. Originally, with this book, I created my own set of flash cards of what I thought was the most important, in the way I wanted them. It caught some of them, but not all of them. Furthermore, it caught instances that should have been detected.
In short, I think it’s a good first step.
For some details, below is a screenshot for Chapter 01, with the anki deck loaded in:
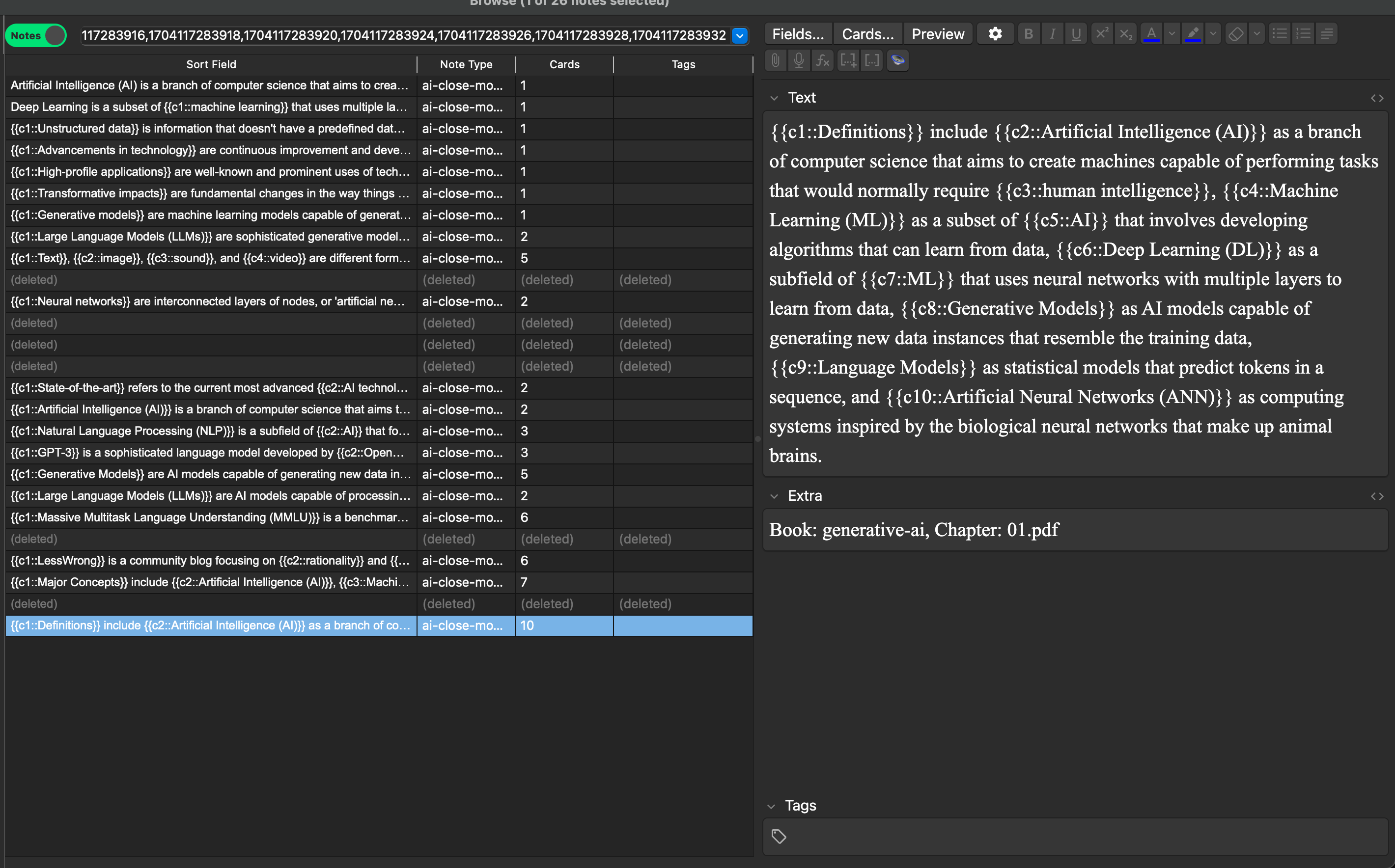
The above is filtered by “note”, and shows the notes that I found less useful, or wouldn’t consider learning are in darker grey (indicating being deleted). There are 26 total notes, of which 6 were deleted. In this run, I didn’t find any that I’d add to the list. In fact, it came up with some really good cloze sentences that I would have struggled to do myself, an example is:
{{c1::Definitions}} include {{c2::Artificial Intelligence (AI)}} as a branch of computer science that aims to create machines capable of performing tasks that would normally require {{c3::human intelligence}}, {{c4::Machine Learning (ML)}} as a subset of {{c5::AI}} that involves developing algorithms that can learn from data, {{c6::Deep Learning (DL)}} as a subfield of {{c7::ML}} that uses neural networks with multiple layers to learn from data, {{c8::Generative Models}} as AI models capable of generating new data instances that resemble the training data, {{c9::Language Models}} as statistical models that predict tokens in a sequence, and {{c10::Artificial Neural Networks (ANN)}} as computing systems inspired by the biological neural networks that make up animal brains.
This is quite amazing, but needs a bit of improvement. First, we wouldn’t test off the word “Definitions”, so I’d remove that close, then decrement the remainder into the following:
Definitions include {{c1::Artificial Intelligence (AI)}} as a branch of computer science that aims to create machines capable of performing tasks that would normally require {{c2::human intelligence}}, {{c3::Machine Learning (ML)}} as a subset of {{c4::AI}} that involves developing algorithms that can learn from data, {{c5::Deep Learning (DL)}} as a subfield of {{c6::ML}} that uses neural networks with multiple layers to learn from data, {{c7::Generative Models}} as AI models capable of generating new data instances that resemble the training data, {{c8::Language Models}} as statistical models that predict tokens in a sequence, and {{c9::Artificial Neural Networks (ANN)}} as computing systems inspired by the biological neural networks that make up animal brains.
All in all, for the entire book, 242 notes (which can contain multiple Clozes - 534 cards entirely) were created.
Where I’m Going from Here
I feel like I’m not done with this project. One issue I ran into is that, sometimes, it provides JSON that can’t be parsed properly. In my example here, I added a “retry” option, that simply does the operation again. This isn’t optimal since it’s wasteful on resources.
There’s an option called a Refine Chain[21], which I think will solve this issue. The general idea is to pass the output for each chapter and have it verify the JSON is correct before it gets to the parsing portion.
Speaking of resource optimization, another optimization is the chunking of the files. With my specific file, I get roughly 1000 (average) tokens per block. This process takes a long time to run, on the magnitude of about an hour or so for the full book. I’ve played with this in the summarization setting where I batched up the documents to no less than 12k tokens, and can bring the time down quite a bit.
Another area I’d like to investigate is better prompts. The prompts (think instructions) are incredibly important. Most of my time when working with workflows is spent here. Even minor changes to a prompt can give drastically different results. This includes even a few words. Collapsing some of the documents, along with better prompts, should yield even better summaries.
Conclusion
Part of why I wrote this article is part how to use LangChain, and the power of LangChain, but it also extends to why AI is quite powerful. For education, especially, AI can be a great boon that I don’t see being leaned into much.
I’ve been using AI for near everything I could think of. This includes for all things coding (both completions, generation of new code), summaries of books/articles, general questions/feedback, and general conversation. I’m also looking into vector store databases, as well as fine-tuning models as well.
References
- Artificial Intelligence
- Atomic Habits
- The Secrets of Consulting
- Generative AI with LangChain
- Generative AI with LangChain - Github Repo, Summarize
- LangChain - Use Cases: Summarization
- Anki - Main Website
- Cloze test - Wikipedia
- LangChain - Document Loader - PDF
- Calibre - Main Page
- TheBloke - MixtralOrochi8x7B
- Mixtral Architecture
- Qualcomm - Quantization
- NVIDIA RTX 6000 Ada Generation
- Text-Generation-WebUI (Github)
- Generative Ai with LangChain - page 50
- LangChain - Components - LLMs
- LangChain - Use Cases - Summarization
- What Are Zero-Shot Prompting and Few-Shot Prompting
- GenAnki (Github)
- LangChain - Refine
