
Introduction
“Temet Nosce” is Latin for “Know Thyself” [1] and is an important philosophical concept [2]. It also appears in “The Matrix” [3].
The interpretation of the phrase can differ, and many authors use it. But, the way I look at it is having a quality of high self-awareness, which develops from self reflection - and is a very important skill [4]. One area of self-awareness is the identification of biases when it comes to conclusions of something one may feel is “true”. This topic can go down quite the rabbit-hole on its own, so to better scope this article, I’m defining “true” in the previous phrase as True in the literal sense. In other words, I won’t deal with the subjective of what an individual feels is true, but an objective truth that can be tested.
This greatly simplifies the scope of this article, but is still a very important tool I rarely find people employing. Often times people will point to an article, or to something they heard, and the objective truth is considerably different than they understand.
Instead of picking on others, though, I want to pick on myself. To show a time where I needed to validate the truth in something, how I went about it, and why it matters.
The Problem
I was recently in a meeting discussing the impact of heaps in queries run by an off-the-shelf reporting tool called Cognos. What we saw was that, for some reports in particular, queries were running very slowly. Some non-clustered indexes were created to try and solve the issue, but through inadequate maintenance and overall changes to the reports, this started to show less promise. We ended up killing the report after 8 minutes.
Which then led to a discovery. In a portion (of the warehouse) for reporting, there were no Clustered indexes, at all. Yeah, we found that incredibly strange. We suspect, given this is an off-the-shelf product, that the optimization was for the ETL work to update, and not for query optimization from a reporting standpoint.
Which then came to one potential proposal (in addition to fixing the way the report was querying), and that was to add Clustered indexes to table after loads were done, and before people would use it. There was quite a bit of promise in this solution in some tests.
One question that came from me at the time was the impact in building/destroying this index. I found an article [5] that described how removing a Clustered index doesn’t result in the reorganization of any pages on disk, and is primarily a meta-data removal. Part of my misreading initially, and part of my needing to prove this fact resulted in a project, largely done in my free time, to test my assumption, my assumption being is that it wasn’t nearly as free as it sounded from the meeting and to validate the article.
Designing the Test
The most important part to testing your assumptions is to create a test that can accurately test the assumption. In my case above, I knew I needed a free SQL server, some test data, and lots of computational time. I also knew that I wanted to share my results (not only with coworkers, but through this article), so I knew it needed to work on GitHub. I also wanted to design it in a way to make it easy to understand, easy to reproduce, and possible to interpret without any tools installed.
A tall order, but by no means that challenging.
Initially the test was to test Clustered indexes primarily, but long term, I also added in Non-Clustered index timings as well. I didn’t have enough data to really run a meaningful test, so I generated my own data. From a data standpoint, I decided to test the perspective from a delta load into this database. Meaning, I would insert in a bunch of data, create a clustered index (which results in pages being reordered), then drop the clustered index, then insert a bunch more records (double initial set), then build the clustered index.
A graphical way to view this is in the following diagram:
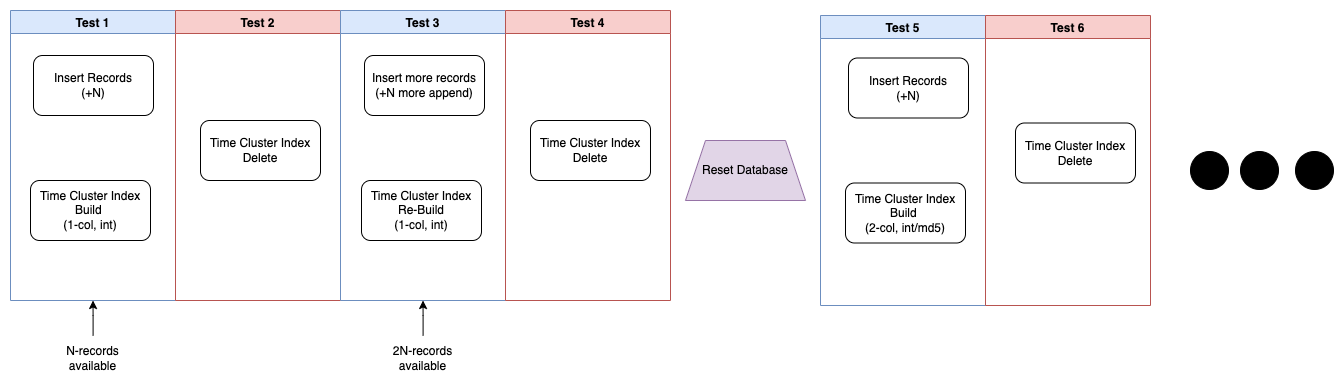
In the above, we have 4 groups of tests, with 4 tests per group. We’re also using 2 sample sizes of 400,000 records, and 1,500,000 records. This is using a single threaded Python instance (for database actions, test data generation is multi-threaded). We generate test data, insert, time the build, delete, insert, rebuild, delete. So by the time we finish with test 4, we have a total of N * 2 records. So 800,000 and 3,000,000 records respectively.
The data is incredibly simplistic consisting of an integer column (used in the clustered index build) that’s random between (1 and 200 * N, and unique), a hash/MD5 column (uuid, unique-ish [6], used in composite cluster with int), and a random sentence/string.
You can find all the code, and more results at:
https://github.com/TheDarkTrumpet/SQL-Heap-Test
Test Execution and Results
Below is taken from the GitHub repository, that has the tests and executions. Odd number tests include inserting, and even number tests are deletions.
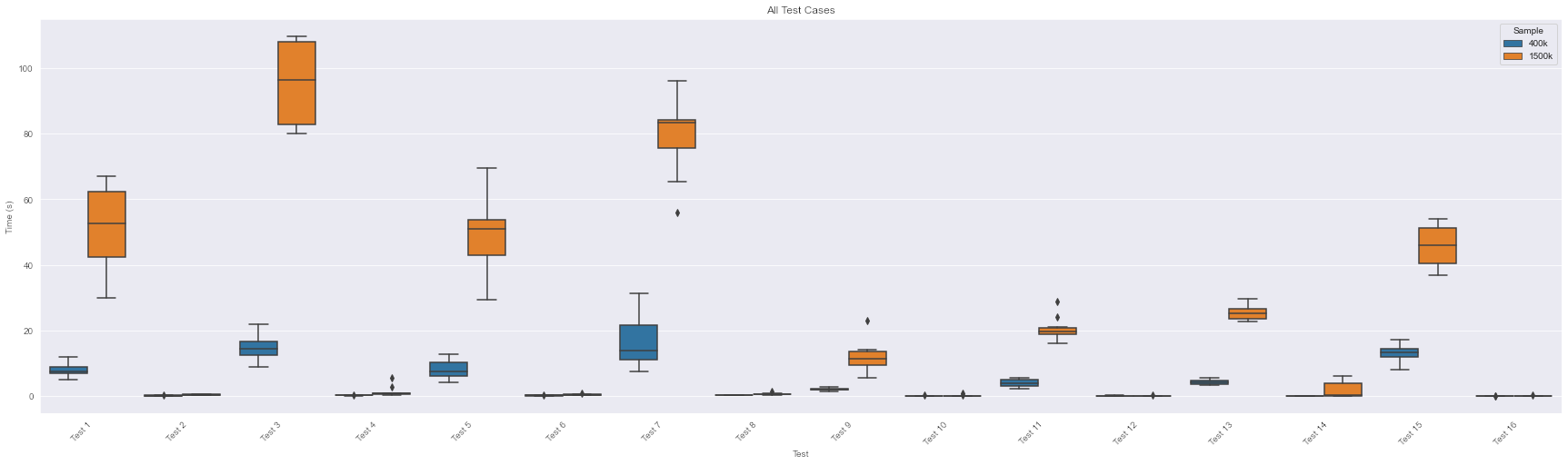
I had a few expectations of what I’d see, and even after running all this, I’m a little surprised by the results. Ignoring the fact I misread the original article, I thought that the deletions (2, 4, 6, ..) consume more resources than they actually did in the end. For Non-clustered indexes they take up more than clustered indexes. Which, shows that page reorganization doesn’t happen. Much like the article [5] said. This seems expected
What’s more interesting in this set is how the clustered index builds happen. My test runs could have been a bit better in telling this story, but there’s enough information to look at. When we’re inserting in 400k records (then building a clustered index), we’re taking about 8 seconds. When we insert another 400k records (test 3, so now at 800k records) and rebuild, we’re taking around 16 seconds. What this tells us is that we rarely touched that first block of records. A similar story looking at the 1.5 mil and 3 mil (test 1 and 3, orange).
We know that little of the first block was touched. This is likely due to a degree with the way I generated the integers (and the range of possible values) that aided in this. We know this because if we were touching each block, then we should expect the build (test 3, blue) to take closer to 30 seconds. The reason for that is because that’s how long the 1.5 mil records (test 1, orange) took to do the initial build, which was 50 seconds (and we take roughly half of that time, and add a bit, so 30 seconds).
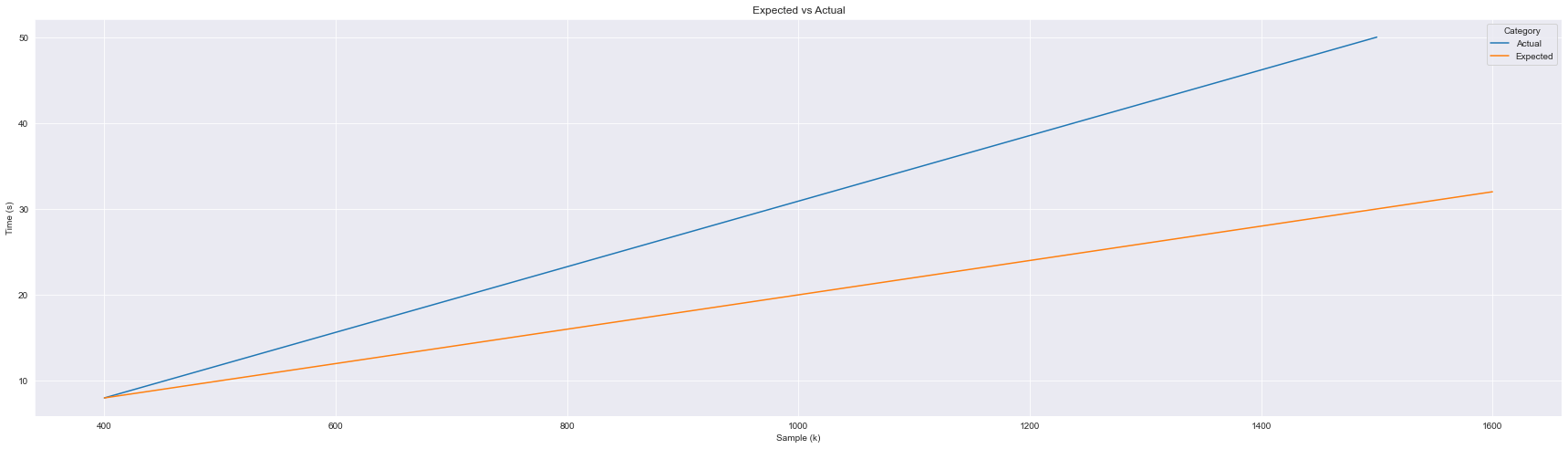
Also interesting is that the clustered index builds are likely not linear in nature. This is illustrated looking at the rebuilds above. Given that 400k or so records took about 8 seconds, we’d expect the following growth pattern, but it grows considerably quicker. The graph below makes this look linear, but I’m willing to bet it’s closer to an exponential curve if specifically tested:
Conclusion and Take-Away
I really believe that assumptions should be limited in nature. Some assumptions can be made with supporting evidence, but there needs to be a degree of confidence in that assumption than simply “I believe” (with no evidence) or “I heard” (where the source has no evidence). In the above story, I took a minor assumption I made, and decided to test it. The results took me by surprise in a few ways, but even more important is that I learned something new. One may expect I learned more about clustered indexes, which is true, but I also learned more than that:
- How to load/run multi-line SQL through SQL Alchemy.
- How to do some minor multi-processing using Python Pools.
Along with learning new skills, I also was able to further practice other skills such as plotting, and presenting results. All of this gained without making it tied to the primary objective, thus not intended.
An overall win.
References
- 1: Wikipedia - Know thyself
- 2: Patrick McGrath Muñiz - “Know Thyself” The most important art lesson of all
- 3: Matrix 4 Humans - Temet Nosce: The Oracle’s Sign In the Matrix
- 4: Psychology Today - Self-Reflective Awareness: A Crucial Life Skill
- 5: Microsoft Technet - Dropping a Clustered Index Will Not Reorganize the Heap
- 6: Stack Overflow - How Unique is UUID
